Foram encontradas 80 questões.
Um problema comum no processamento de texto é o tratamento de termos compostos por mais de um token, tais como “Ministério Público”, tal que represente uma unidade linguística distinta, em particular na construção de modelos de linguagem.
Considerando o problema acima descrito, a alternativa que apresenta uma técnica usada para sua resolução é:
Provas
O método Latent Dirichlet Allocation (LDA) é popularmente utilizado para a construção de modelos de tópicos devido a sua flexibilidade e robustez, particularmente em grandes quantidades de texto. Ao mencionar a escolha do LDA em um projeto, um analista foi questionado sobre que aspectos caracterizam a flexibilidade do modelo, especialmente em comparação a um modelo pLSA.
O analista respondeu corretamente:
Provas
Um modelo semântico vetorial foi criado com a seguinte definição:
!$ v(w)_i = tf(w, d_i) \cdot idf(w, D) !$
onde !$ v !$ é o vetor correspondente à palavra !$ w !$, !$ d_i !$ é o i-ésimo documento da coleção !$ D !$ de artigos da Wikipédia, ordenados alfabeticamente por título, e !$ tf !$ e !$ idf !$ são, respectivamente, as funções de frequência de termo e inverso da frequência em documentos.
A alternativa que classifica corretamente o modelo acima descrito e apresenta a razão correta para a classificação é:
Provas
A atividade de classificação de documentos envolve um grande número de tarefas de processamento de linguagem natural, o que pode levar a dúvidas quanto a sua aplicação.
A alternativa que contém apenas tarefas que sejam exemplos de classificação de documentos é:
Provas
Para realizar o agrupamento de um conjunto de 4 observações (A, B, C e D) foi decidido usar o método de agrupamento hierárquico aglomerativo com ligação simples (single-linkage).
A matriz de distância inicial entre os elementos é apresentada a seguir.
| A | B | C | D | |
| A | 0.0 | 3.5 | 4.0 | 1.5 |
| B | 4.0 | 0.0 | 0.5 | 3.0 |
| C | 3.0 | 1.0 | 0.0 | 3.5 |
| D | 2.0 | 2.5 | 3.5 | 0.0 |
Considerando essas informações, a matriz de distância obtida após o primeiro passo do agrupamento é:
Provas
A aplicação do algoritmo AdaBoost, utilizando classificadores SVM, permitiu a obtenção de um modelo classificador de sinais sonoros com excelente precisão. Entretanto, esse modelo possui requisitos computacionais além da capacidade da plataforma onde se deseja aplicá-lo.
Considerando o problema acima descrito, a técnica a ser utilizada para contornar o problema é:
Provas
O método random forests para classificação ou regressão potencializa alguns benefícios das árvores de decisão e por isso é preferido em certas situações.
O uso de random forests seria vantajoso em relação à árvore de decisão no seguinte caso:
Provas
Uma biblioteca está classificando os seus frequentadores em grupos literários para facilitar a aquisição e a organização dos livros. Isso foi feito aplicando o algoritmo KNN ao banco de dados de usuários da biblioteca, incluindo alguns dos campos de informação como atributos, tais como idade e nível de formação acadêmica. Em um experimento, uma segunda classificação foi feita usando um conjunto maior de atributos, incluindo ambos de maior ou menor relevância percebida com relação aos grupos definidos.
A segunda classificação tende a ser:
Provas
Em um trabalho de pesquisa, as idades das pessoas são: 23, 27, 32, 33, 34, 35, 36, 38, 42, 56 e 58. Deseja-se construir um boxplot similar ao gráfico a seguir.
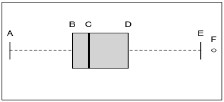
No boxplot acima, os valores das estatísticas nas posições indicadas pelas letras A, B, C, D, E e F são:
Provas
Uma prefeitura recebeu uma denúncia de que o número de autuações feitas pela equipe de fiscalização variava conforme o dia da semana. Para verificar a procedência da denúncia, as autuações foram agregadas por dia de semana, como mostra a tabela a seguir.
| Segundas Terças Quartas Quintas Sextas Sábados Domingos | 6 12 9 8 15 13 7 |
Realizando um teste estatístico adequado para verificar se essas autuações ocorrem com a mesma frequência, teremos:
Provas
Caderno Container