Foram encontradas 70 questões.
Um estatístico construiu o seguinte código em SQL:

Considerando o exposto, é correto afirmar que esse programa está
Provas
Um estatístico deseja ler um arquivo CSV no software Python. Para isso, ele escreveu os seguintes comandos:

O código exposto apresenta, na 4ª linha, erro. Qual das alternativas corrige esse erro?
Provas
Um estatístico acredita que existe uma relação entre as variáveis quantitativas X e Y. Para verificar essa informação, ele fez o seguinte programa em R:

É correto afirmar que as linhas de programa fornecem, respectivamente, os seguintes resultados:
Provas
A análise de componentes principais é uma técnica de redução de dados em que o objetivo principal é a construção de uma combinação linear das principais variáveis que representa a totalidade. Então, nesse tipo de análise, são aplicados os seguintes gráficos:
Provas
Em situações que a variável resposta \( y \)\( i \) é dicotômica, tem-se que \( y \)\( i \) segue uma distribuição de Bernouli com parâmetro p, ou seja, \( y \)\( i \)~\( B \)\( e \)\( r \)(\( \pi \)\( i \)), para \( i \) = \( 1 \), … , \( n \). Suponha que uma covariável \( x \)\( i \) está associada para cada observação i. Usando a função de ligação logito, temos que ![]() . Com base no exposto, é correto afirmar que o modelo logístico é dado por
. Com base no exposto, é correto afirmar que o modelo logístico é dado por
Provas
Um estatístico observou, por meio do diagrama de dispersão, uma correlação entre as variáveis x e y. Assim, ele decidiu fazer uma análise de regressão, e o resultado fornecido pelo software R está descrito a seguir:

De acordo com esses resultados, é correto afirmar que o modelo de regressão estimado, o coeficiente de determinação e a estatística do teste de significância do modelo de regressão, respectivamente, são dados por:
Provas
Quando o gráfico de dispersão sugere um relacionamento aproximadamente linear entre as duas variáveis, o modelo indicado é representado pela seguinte equação:
\( y \)\( i \) = \( \beta \)\( o \) + \( \beta \)\( 1 \)\( x \)\( i \) + \( \varepsilon \)\( i \) ,
em que \( y \)\( i \) é o i-ésimo valor da variável dependente ou resposta; \( \beta \)\( o \) e \( \beta \)\( 1 \) são os parâmetros do modelo ou coeficientes de regressão; \( x \)\( i \) é o i-ésimo valor da variável independente ou covariável; \( \varepsilon \)\( i \) é o iésimo erro aleatório. Considerando que os \( \varepsilon \)\( i \) são idênticos, independentes e distribuídos conforme o modelo Normal com média 0 e variância ![]() , ou seja,
, ou seja, ![]() , é correto afirmar que
, é correto afirmar que
Provas
Sabe-se que, ao realizar um teste de hipóteses, está-se sujeito a cometer erros. O Erro tipo I consiste em rejeitar a hipótese nula quando, na verdade, ela é verdadeira e o Erro tipo II consiste em não rejeitar a hipótese nula quando, na verdade, ela é falsa. Sabe-se também que a função poder do teste é a probabilidade de que o procedimento do teste leve a rejeição da hipótese nula, dado um valor do parâmetro. Então, a probabilidade do Erro tipo I e do Erro tipo II, e a função poder do teste são, respectivamente, dadas por:
Provas
Sabe-se que uma forma de construir intervalos de confiança para os parâmetros é utilizando quantidade pivotais. Sabe-se também que \( Q \)(\( X \); \( \theta \)) é uma quantidade pivotal, ou seja, uma função de (X1,...,Xn) e \( \theta \), se a de distribuição \( Q \)(\( X \); \( \theta \)) não depende de \( \theta \). Então, é correto afirmar que a quantidade pivotal dada por
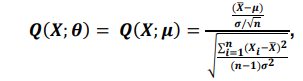
segue a distribuição
Provas
Sabe-se que a eficiência de um estimador \( \hat{\theta} \), não viesado para o parâmetro \( \theta \), é dado por:
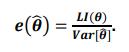
Considerando a expressão apresentada, é correto afirmar que as medidas \( L \)\( I \)(\( \theta \)) e \( V \)\( a \)\( r \)[\( \hat{\theta} \)] são respectivamente
Provas
Caderno Container