Foram encontradas 200 questões.
Em relação aos repositórios de dados data lake e data warehouse em arquiteturas de Big Data, analise
as afirmativas a seguir.
I. Um data lake é caracterizado por priorizar a ingestão de dados em seu formato original, permitindo armazenar dados estruturados, semiestruturados e não estruturados, com uso de abordagens de schema-on-read.
II. Um data warehouse adota schema-on-write, exigindo modelagem prévia, como esquemas em estrela ou floco de neve, para suportar consultas analíticas otimizadas.
III. A simples adoção de schema-on-write em um data lake o caracteriza automaticamente como um data warehouse.
É verdadeiro o que se afirma em
I. Um data lake é caracterizado por priorizar a ingestão de dados em seu formato original, permitindo armazenar dados estruturados, semiestruturados e não estruturados, com uso de abordagens de schema-on-read.
II. Um data warehouse adota schema-on-write, exigindo modelagem prévia, como esquemas em estrela ou floco de neve, para suportar consultas analíticas otimizadas.
III. A simples adoção de schema-on-write em um data lake o caracteriza automaticamente como um data warehouse.
É verdadeiro o que se afirma em
Provas
Questão presente nas seguintes provas
No Extreme Programming (XP), práticas que dão suporte à propriedade coletiva do código incluem
Provas
Questão presente nas seguintes provas
Em relação aos eventos do Scrum, analise as afirmativas a seguir.
I. A Sprint Review tem como foco principal identificar melhorias no processo de trabalho e definir ações de aprimoramento para a próxima Sprint.
II. O Scrum master tem autoridade para cancelar uma Sprint quando avalia que a Meta da Sprint se tornou obsoleta.
III. A Daily Scrum tem como propósito inspecionar o progresso em direção à Meta da Sprint e ajustar o Sprint Backlog conforme necessário.
É verdadeiro o que se afirma em
I. A Sprint Review tem como foco principal identificar melhorias no processo de trabalho e definir ações de aprimoramento para a próxima Sprint.
II. O Scrum master tem autoridade para cancelar uma Sprint quando avalia que a Meta da Sprint se tornou obsoleta.
III. A Daily Scrum tem como propósito inspecionar o progresso em direção à Meta da Sprint e ajustar o Sprint Backlog conforme necessário.
É verdadeiro o que se afirma em
Provas
Questão presente nas seguintes provas
No que tange a preparação de dados no Power Query, a linguagem M é utilizada para
Provas
Questão presente nas seguintes provas
No âmbito de Business Intelligence, sistemas OLAP são projetados para
Provas
Questão presente nas seguintes provas
Com relação à ingestão de dados via filas de mensagens em pipelines de dados, considere o cenário a
seguir. Um pipeline consome eventos de uma fila de mensagens que pode entregar mensagens fora de
ordem e com política de entrega “pelo menos uma vez”, o que pode ocasionar o recebimento do mesmo
evento mais de uma vez. Nesse contexto, a medida mais adequada para evitar efeitos duplicados no
processamento é
Provas
Questão presente nas seguintes provas
Com relação à orquestração de dados, analise as afirmativas a seguir.
I. Um agendador baseado em tempo, como o cron, dispara tarefas conforme um horário configurado.
II. Um sistema de orquestração pode iniciar tarefas quando as dependências de um grafo acíclico direcionado (DAG) são satisfeitas e pode sinalizar falhas durante a execução.
III. Um sistema de orquestração pode manter histórico de execuções e suportar reprocessamento de períodos anteriores por meio de backfill.
É verdadeiro o que se afirma em
I. Um agendador baseado em tempo, como o cron, dispara tarefas conforme um horário configurado.
II. Um sistema de orquestração pode iniciar tarefas quando as dependências de um grafo acíclico direcionado (DAG) são satisfeitas e pode sinalizar falhas durante a execução.
III. Um sistema de orquestração pode manter histórico de execuções e suportar reprocessamento de períodos anteriores por meio de backfill.
É verdadeiro o que se afirma em
Provas
Questão presente nas seguintes provas
Em relação ao aprendizado de máquina não supervisionado, analise as afirmativas a seguir.
I. No algoritmo k-means, a atribuição de cada instância a um grupo é feita pela menor distância ao centroide, e os centroides são atualizados como a média das instâncias atribuídas a cada grupo, de forma iterativa até um critério de parada.
II. O coeficiente de silhouette é uma métrica de avaliação de agrupamento, baseada em a(i) (distância média da instância i ao seu grupo) e b(i) (menor distância média de i a um grupo vizinho), assumindo valores no intervalo [−1,1].
III. O algoritmo DBSCAN é um método de agrupamento baseado em centroides, no qual o número de grupos k é definido previamente.
É verdadeiro o que se afirma em
I. No algoritmo k-means, a atribuição de cada instância a um grupo é feita pela menor distância ao centroide, e os centroides são atualizados como a média das instâncias atribuídas a cada grupo, de forma iterativa até um critério de parada.
II. O coeficiente de silhouette é uma métrica de avaliação de agrupamento, baseada em a(i) (distância média da instância i ao seu grupo) e b(i) (menor distância média de i a um grupo vizinho), assumindo valores no intervalo [−1,1].
III. O algoritmo DBSCAN é um método de agrupamento baseado em centroides, no qual o número de grupos k é definido previamente.
É verdadeiro o que se afirma em
Provas
Questão presente nas seguintes provas
Em aprendizado de máquina supervisionado, o fenômeno overfitting ocorre quando o modelo apresenta
Provas
Questão presente nas seguintes provas
Em um problema de classificação binária, P representa a classe positiva e N representa a classe
negativa. A matriz de confusão a seguir apresenta as linhas como classes reais e as colunas como classes
preditas, com o número de instâncias (amostras) em cada caso.
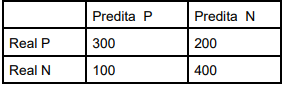
Os valores de precisão e recall para a classe P, nessa ordem, são
Os valores de precisão e recall para a classe P, nessa ordem, são
Provas
Questão presente nas seguintes provas
Cadernos
Caderno Container