Foram encontradas 32.774 questões.
Disciplina: Estatística
Banca: FAU-UNICENTRO
Orgão: Pref. Bom Jesus do Sul-PR
Provas
Disciplina: Estatística
Banca: FAU-UNICENTRO
Orgão: Pref. Bom Jesus do Sul-PR
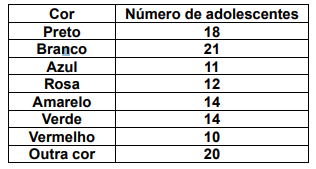
Com base nestas informações, é correto afirmar que a moda dos dados é a cor:
Provas
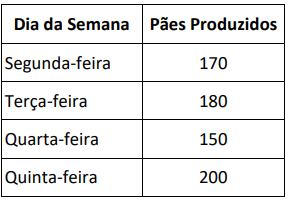
Com base nas informações do quadro, assinalar a alternativa que corresponde à média de produção diária de pães.
Provas
Provas
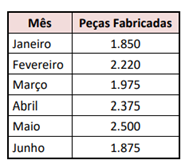
Com base nos dados apresentados, assinalar a alternativa INCORRETA.
Provas
Provas
- Estatística DescritivaMedidas de Tendência CentralMédias
- Estatística DescritivaMedidas de Tendência CentralMediana
Durante 6 meses a equipe de vendas de um frigorífico monitorou o preço da arroba do boi gordo na cidade de Marquinho. Os valores são:
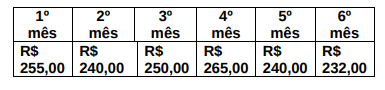
Com base nestas informações, os valores da média e da mediana de preço são respectivamente iguais a:
Provas
Quanto aos valores da nova média e mediana com as 24 notas, é correto afirmar:
Provas
Provas
Um fabricante de certo equipamento diz que o tempo médio de sobrevida de seu produto é de 720 dias. Para verificar se a afirmação do fabricante estava correta, foi realizado um teste de hipótese.
Para tanto, foi selecionado uma amostra de 25 equipamentos, em que se observou que o tempo médio e o desvio padrão dessa amostra foi de, aproximadamente, 700 dias e 20 dias respectivamente.
Levando em consideração a potência do teste, assinale a opção que apresenta a hipótese alternativa mais adequada para a realização do teste.
Provas
Caderno Container