Foram encontradas 32.745 questões.
Um Professor do IFCE solicita que os alunos
analisem dados numéricos coletados por sensores
no campus, sem rótulos ou categorias prédefinidas.
O objetivo é identificar automaticamente
agrupamentos naturais nos dados, revelando
padrões de similaridade sem utilizar informações
externas. Para isso, o docente orienta que os
estudantes escolham, entre os algoritmos
estudados, aquele adequado para realizar
clusterização em contexto não supervisionado.
Diante desse contexto, assinale a alternativa que
apresenta corretamente o algoritmo que os alunos
devem escolher.
Provas
Questão presente nas seguintes provas
Um programa de melhoramento genético de
bovinos leiteiros identificou variação significativa
na eficiência alimentar do rebanho. Para apurar a
base genética dessa característica, foi conduzido
um experimento de associação genômica ampla
(GWAS – Genome-Wide Association Study),
utilizando milhares de marcadores SNP
distribuídos ao longo do genoma. Os resultados
apontaram regiões cromossômicas
estatisticamente associadas à característica, o que
sugere a presença de possíveis QTLs (Quantitative
Trait Loci). Considerando os fundamentos
aplicados ao melhoramento animal, assinale a
alternativa correta.
Provas
Questão presente nas seguintes provas
O método BLUP (Best Linear Unbiased Prediction)
é muito utilizado em programas de avaliação
genética animal para estimar valores genéticos.
Considerando os fundamentos estatísticos e
genéticos do BLUP, assinale a alternativa correta.
Provas
Questão presente nas seguintes provas
Em um estudo sobre a produção de milho de duas
lavouras utilizadas para a produção de silagem
para bovinocultura leiteira, foram calculadas a
variância e o desvio-padrão das colheitas
anualizadas. Considerando esses conceitos,
assinale a alternativa correta a respeito da
interpretação desses dados.
Provas
Questão presente nas seguintes provas
O uso de média, variância e desvio-padrão é
fundamental na análise estatística, provendo uma
base para entender e interpretar os dados dentro
de uma população. Em um experimento de nutrição
animal, foram coletados os dados de ganho de
peso de 30 suínos em confinamento com
determinada dieta por período controlado,
resultando nas médias, variâncias e
desvios-padrão. Nesse sentido, sobre a média dos
pesos, assinale a alternativa correta.
Provas
Questão presente nas seguintes provas
- Estatística DescritivaMedidas de Dispersão
- Estatística DescritivaMedidas de Tendência Central
- Estatística InferencialIntervalos de confiança
A presença de água no querosene de aviação pode
levar ao bloqueio de filtros por gelo, e a
coulometria Karl Fischer é o padrão para medir
esses níveis extremamente baixos de umidade.
Considere que o laboratório de química analítica de
uma instituição de ensino tenha ficado
responsável pela quantificação da concentração
de água no querosene de aviação oriundo de um
lote que fora interditado. Considere, ainda, que a
determinação da concentração de água no
querosene de aviação foi realizada em quatro
réplicas oriundas do lote interditado.
A tabela a seguir apresenta os resultados das
concentrações por meio da coulometria Karl
Fischer. No relatório encaminhado às autoridades
responsáveis, o químico afirmou que o valor do
desvio-padrão para essas amostras é igual a
2,9 ppm e a distribuição desses dados pode ser
assumida normal.
| Amostra | Concentração (ppm) |
|---|---|
| 1 | 98 |
| 2 | 96 |
| 3 | 95 |
| 4 | 91 |
Provas
Questão presente nas seguintes provas
A presença de água no querosene de aviação pode
levar ao bloqueio de filtros por gelo, e a
coulometria Karl Fischer é o padrão para medir
esses níveis extremamente baixos de umidade.
Considere que o laboratório de química analítica de
uma instituição de ensino tenha ficado
responsável pela quantificação da concentração
de água no querosene de aviação oriundo de um
lote que fora interditado. Considere, ainda, que a
determinação da concentração de água no
querosene de aviação foi realizada em quatro
réplicas oriundas do lote interditado.
A tabela a seguir apresenta os resultados das
concentrações por meio da coulometria Karl
Fischer. No relatório encaminhado às autoridades
responsáveis, o químico afirmou que o valor do
desvio-padrão para essas amostras é igual a
2,9 ppm e a distribuição desses dados pode ser
assumida normal.
| Amostra | Concentração (ppm) |
|---|---|
| 1 | 98 |
| 2 | 96 |
| 3 | 95 |
| 4 | 91 |
Provas
Questão presente nas seguintes provas
A presença de água no querosene de aviação pode
levar ao bloqueio de filtros por gelo, e a
coulometria Karl Fischer é o padrão para medir
esses níveis extremamente baixos de umidade.
Considere que o laboratório de química analítica de
uma instituição de ensino tenha ficado
responsável pela quantificação da concentração
de água no querosene de aviação oriundo de um
lote que fora interditado. Considere, ainda, que a
determinação da concentração de água no
querosene de aviação foi realizada em quatro
réplicas oriundas do lote interditado.
A tabela a seguir apresenta os resultados das
concentrações por meio da coulometria Karl
Fischer. No relatório encaminhado às autoridades
responsáveis, o químico afirmou que o valor do
desvio-padrão para essas amostras é igual a
2,9 ppm e a distribuição desses dados pode ser
assumida normal.
| Amostra | Concentração (ppm) |
|---|---|
| 1 | 98 |
| 2 | 96 |
| 3 | 95 |
| 4 | 91 |
Provas
Questão presente nas seguintes provas
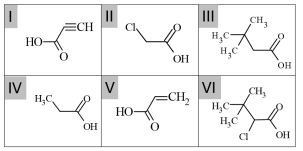
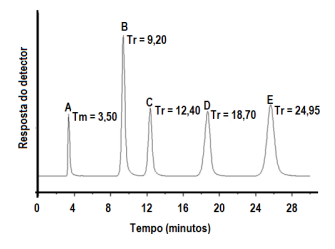
Em um laboratório de química analítica, a análise
de quatro compostos hipotéticos (B, C, D e E) foi
conduzida a partir da cromatografia gasosa
acoplada à espectrometria de massas. A figura a
seguir ilustra o cromatograma dessa análise, o
qual mostra a medição do tempo morto (Tm) da
análise e dos tempos de retenção (Tr) desses
quatro compostos.
Provas
Questão presente nas seguintes provas
Intervalo de confiança é uma faixa de valores utilizado para
estimar um parâmetro populacional desconhecido com um
determinado nível de confiança. Na análise estatística de
resultados laboratoriais e experimentais, intervalos de
confiança amplos indicam
Provas
Questão presente nas seguintes provas
Cadernos
Caderno Container